Suite à mon précédent billet sur Btrfs et la compression, je me suis demandé : et pour mes sauvegardes avec Borg Backup, c’est quoi la meilleure option de compression ?
C’est quoi Borg Backup ?
Un outil de sauvegarde très puissant, gérant la compression, la déduplication et le chiffrement. Je vous invite à le découvrir chez Cascador et sur le super wiki de SebSauvage.
PS: malheureusement, il manque encore d’un vrai utilitaire graphique pour ne pas passer par la ligne de commande… Pour une solution similaire mais avec une interface graphique, jetez un œil à Kup Backup (guide d’utilisation).
Correction: on me rappelle l’existence de Vorta comme interface graphique à Borg 🙂 . L’essentiel y est, mais je le trouve encore un poil limité et fait pour gérer un serveur.
On a le choix entre 4 algorithmes de compression, et plusieurs niveaux de compression pour certains d’entre eux. Que choisir ? 🤔
La documentation est un peu succincte (et pas si évidente à trouver) sur la question. En particulier sur l’algorithme Zstandard, qui est un peu touche à tout.
J’ai donc cherché à comparer les différents algorithmes de compression en cherchant à déterminer quelle était la ou les options optimales, selon les cas d’usages.
On y va ? 😃
Avertissement
Ce test n’a pas la prétention d’être exhaustif, de couvrir tous les cas d’usage, ni de fournir des mesures très précises des performances ou une conclusion définitive sur le choix de « la meilleure option ».
Faute de trouver les ressources suffisantes en ligne, j’ai voulu mesurer quelle option était la plus optimale dans mon cas particulier. Et je vous partage mes résultats car je trouve que c’est trop peu documenté en ligne.
Libre à vous de reproduire le même test dans vos conditions réelles, rien ne sera plus adapté à votre situation 😉
Méthodologie
Matériel utilisé
Côté processeur : un Ryzen 5 3600, tournant à 3,6Ghz de base et autour de 4,1Ghz au maximum de ses performances d’usine.
Ce processeur est intéressant comme élément de comparaison, en effet il représente le milieu de gamme actuel d’AMD, et plutôt la tranche du haut de gamme du marché grand public, d’autant plus que c’est un processeur récent.
Dans le test cité plus haut, vous avez une idée des performances pour un vieux processeur haut de gamme d’AMD, qui correspond plus à l’entrée de gamme actuelle. Je note d’ailleurs que l’écart de performances est assez faible.
Précision technique – performances du processeur
Borg Backup n’utilise toujours qu’un seul thread, c’est-à-dire qu’il ne calcule qu’avec un cœur logique. Autrement dit, sur mon processeur, 1 seul des 12 cœurs sera utilisé. Donc seules les performances en mono-cœur comptent.
Côté stockage : un SSD Intel 660p 512Go, de type NVMe c’est-à-dire un SSD branché sur un port PCI-E (3.0), qui permet des débits bien supérieurs au SATA 3. Ce qui permet de m’assurer que la sauvegarde ne sera pas limitée par le stockage.
Conditions du test
Le test a été réalisé sur une distribution Linux (Kubuntu 20.10). C’est ma machine principale, elle était donc utilisée en parallèle (ex: Firefox était actif) ce qui introduit peut-être un peu de variabilité dans les résultats, mais est aussi plus fidèle aux conditions réelles d’utilisation (en multi-tâche sur un ordinateur grand public) et surtout la charge de calcul et en écriture était très faible. C’est négligeable.
Parmi les 4 types d’algorithmes qui sont disponibles, j’ai testé les compressions suivantes :
- Zstandard, abrégé zstd dans la suite de ce billet, à plusieurs niveaux de compression entre 1 et 22 (le niveau maximum). Et sans forcément tester tous les intermédiaires, d’après les découvertes du précédent test.
A priori c’est le plus rapide, au moins dans les premiers niveaux de compression. Pour les niveaux les plus élevés, ce n’est pas évident.
Pour information le niveau est celui par défaut (si vous n’en précisez pas un autre). - zlib : aux niveaux de compression 3 et 9 (le maximum). C’est un algorithme a priori assez intermédiaire. Le niveau par défaut est le 6 (non testé).
- lzma : a priori celui qui compresse le mieux, mais aussi le plus lent. uniquement au niveau 6 (le niveau par défaut, et le plus élevé).
Lz4 n’a pas été testé. Il compresse trop peu pour mon besoin d’archivage.
J’ai également testé l’option « auto » qui en théorie permet de détecter à l’avance ce qui n’est pas compressible, et d’éviter de perdre du temps dessus.
Le test en lui-même
C’est très simple : sur un nouveau dépôt Borg, lancer une sauvegarde (avec l’option –stats pour avoir un résultat complet) pour chaque paramétrage. Entre deux sauvegardes, il faut supprimer la précédente, sinon c’est quasi instantané – et oui, borg déduplique ! 😉 🥳
Le fichier utilisé : un profil Firefox, regroupé dans un archive format .tar de 5,45Go. Il a l’avantage de mélanger des fichiers bien compressibles (texte, base de données…) et d’autres moins (images) et de représenter à peu près des fichiers courants sur un ordinateur.
Limites de ma méthodologie:
- Je n’utilise qu’un seul (groupe de) fichier(s). Les différents algorithmes ont peut-être des champs de prédilection, et ça sera invisible sur mon test. On ne peut pas affiner selon le type de fichier à compresser, par exemple. Mais cela reste relativement représentatif d’un corpus de fichier « courant ».
- Les tests n’ont pas été reproduits. Mais j’ai testé sur un algorithme, avec 5 valeurs très similaires d’affilés, j’ai estimé que c’était inutile de le faire.
- Le fichier est assez petit, certains algorithmes ont des temps d’exécution tellement faibles qu’un petit aléa peut faire bouger les temps d’exécution de plusieurs %.
Résultats
Performances brutes
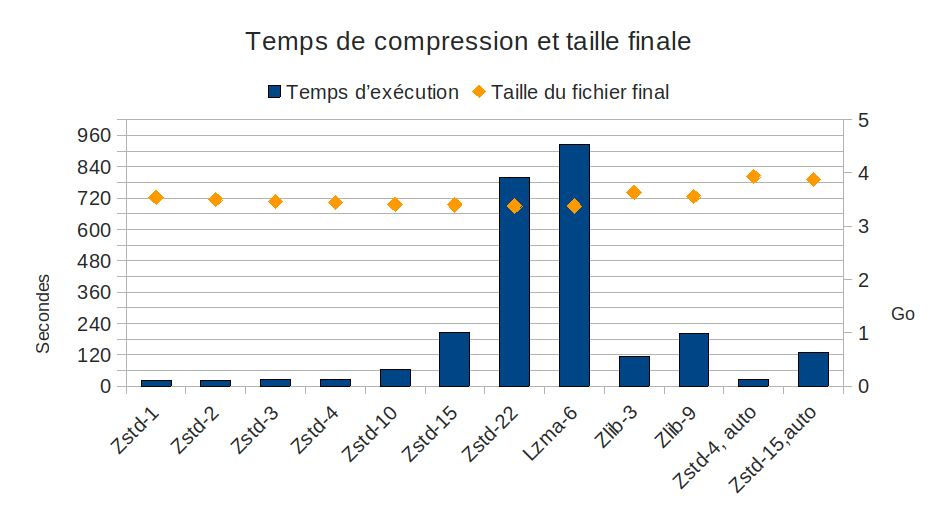
Le résultat est sans appel pour zlib et lzma: ils sont nuls ! *mic drop*
On voit aussi que l’option auto aboutit à un gain de temps, mais qui s’accompagne d’une moindre compression, qui n’est pas compensée par le temps gagné (ex: zstd-15-auto est 6 fois plus lent que zstd-1, pour des fichiers 10% plus gros).
Maintenant, entre les différentes options de zstd, ce n’est pas très clair… Ça l’est plus avec les vitesses de traitement :
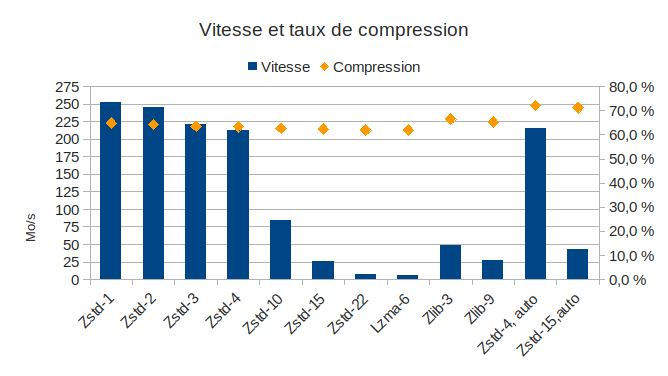
Oui, il y a des rapports de 1 à 10 voire 20 entre les algorithmes les plus rapides et les plus lents. Pour quelques % de compression en plus…
On voit ici que les niveaux 1 à 4 de zstd se tiennent dans un mouchoir de poche (une gamme de 10% en vitesse, 2% en compression). Ensuite, les performances s’écroulent, pour un taux de compression à peine inférieur.
Pourquoi c’est bien plus lent que dans ton billet sur Btrfs ?
Je parie que des petit⋅es malin⋅es l’ont remarqué : les vitesses ici sont bien plus faibles que lors des tests de compression avec Btrfs ? Et bien parce que Borg ne fait pas que de la compression, mais aussi de la déduplication et du chiffrement. Surtout, il ne tourne que sur un cœur, là où Btrfs exploitait les 12.
Et en effet, c’est environ 11 fois plus lent (oui, doubler le nombre de cœur ne fait pas exactement doubler les performances).
Pourquoi ne pas tester sans déduplication et chiffrement ? Parce que ça ne correspond pas à mon cas d’usage, et que l’estimation du temps (et des différences entre algorithmes) serait alors surévaluée.
Le taux de compression
Zlib est inutile, il compresse moins que zstd et moins vite. Lzma aussi est inutile, il compresse pile autant que zstd-22 mais 16% moins vite.
Le taux de compression est plutôt stable entre les différents niveaux de compression zstd : 3% d’écart entre 1 et 22 (le minimum et le maximum), et 2% entre les niveaux 3 et 22. Par contre le temps d’exécution diffère fortement : on note que la compression maximale (zstd-22) est très proche de zstd-15 (0,6% d’écart) mais « coûte » 4 fois plus de temps ! Pire, entre zstd-10 et zstd-15, les 0,2% d’écart coûtent 3,3 fois plus de temps !
Qu’est-ce que ça donnerait en «situation réelle»
Oui parce que c’est bien gentil comme test, mais des variations de quelques secondes et quelques % de compression sur 5Go, c’est pas bien parlant…
Les mauvaises langues, je vous vois, donnez là au chat 😉
C’est vrai que quand on fait une sauvegarde, d’autant plus avec un tel outil (qui réduit fortement la taille des données) et avec l’augmentation quasi-continue des tailles des fichiers, c’est souvent bien plus de quelques Go… Quoiqu’avec la déduplication, pour un même ensemble de fichier une première sauvegarde de 500Go sera suivi d’une autre d’à peine quelques Go… 😀
Très bien, alors regardons ce que ça donnerait si je l’avais fait pour 100Go (nb: j’ai juste fait une multiplication, pas une vraie mesure) :
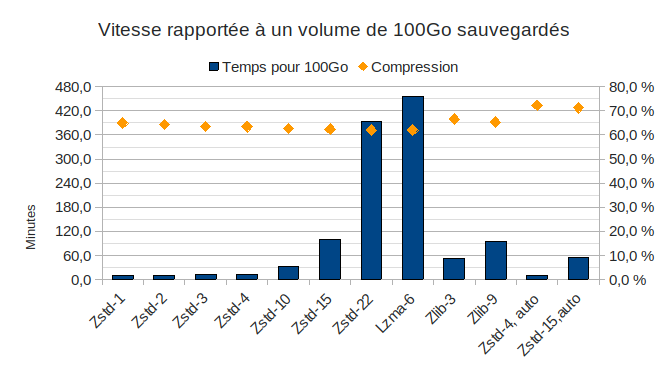
Là on commence à se rendre compte de l’écart gigantesque entre certaines valeurs…
Et de l’augmentation exponentielle du temps de calcul pour chaque petit pourcentage de compression gagné…
Revenons sur les différences de taux de compression: un passage de zstd-1 (qui traite 100Go en 10min) à zstd-3 fait gagner 2% de compression, contre 2 minute d’exécution supplémentaire… pour 100Go. Un passage de zstd-10 à zstd-22 fait gagner 0,6% de compression, contre 6 heures d’exécution supplémentaires !
Je suis bien content de ne pas avoir fait le test avec 100Go ! 🤣 😅
NB: n’oubliez pas que ce sont des temps donnés pour ma machine, en particulier un certain processeur, et pour un certain fichier…ne prenez pas ces valeurs pour argent comptant !
Données non mesurées
Je n’ai pas mesuré précisément la charge du processeur. Par contre, elle était grosso modo de 100% d’un cœur sur la durée de la sauvegarde. Donc en première approximation, le facteur déterminant c’est le temps d’exécution, pas l’algorithme.
Je n’ai pas mesuré la consommation en mémoire.
Conclusion
La compression zstd est toujours la plus rapide à compression égale, et c’est aussi celle qui compresse le plus dans l’absolu. Autrement dit, elle permet de sauvegarder plus vite (à taux de compression équivalent) ou de compresser plus (sur une même durée).
Zlib n’est pas compétitif, et Lzma est complètement aux fraises tellement il est lent (et consomme beaucoup de ressource et d’énergie…).
Maintenant, quel niveau de compression zstd choisir ?
Le taux de compression est très similaire entre les différentes compressions zstd, à tel point que la différence est négligeable sauf pour de très gros volumes de données (quelques Go tous les 100Go).
Je vois 3 scénarios:
- Vous voulez aller vite (ou votre processeur n’est pas assez performant ou surchauffe): zstd-1, peut-être même lz4.
- Le scénario du compromis, le plus courant : zstd-3 (c’est-à-dire la valeur par défaut, bien choisie). Ce n’est pas le plus rapide, mais la différence avec zstd est faible (<20%) pour un gain de 2% de compression (20Go/To).
Sur une sauvegarde très courte (type sauvegarde hebdomadaire) le temps perdu est négligeable, pour une sauvegarde longue on est rarement à 10min près, et le gain est intéressant. - Vous avez de gros besoins en compression, qui passent devant des temps de calcul plus long (et la chauffe/surconsommation engendrée): zstd-10 (+1% de compression par rapport à zstd-3, c’est très relatif…), et ça vous prendra 3 fois plus de temps. Ne montez pas au dessus, 0,2 ou 0,4% (4Go/To!) de compression en plus pour 3 ou 15 fois plus de temps, ça n’en vaut pas la peine.
Enfin, comme pour Btrfs, l’option (auto) -qui permet de déterminer à la volée ce qui n’est pas à compresser- se révèle contre-productive pour la compression.
Hello, concernant les interfaces graphiques y a du neuf.
Pika backup à l’air assez facile à utiliser.
Et pour les très grands débutants, j’ai crée borg-zenity, qui n’intègre que l’essentiel.
Super, merci pour cet article qui m’a bien guidé !
Les graphes de temps étant d’une grande dispersion, il est assez dur de lire les valeurs faibles ; peut-être utiliser une échelle log sur les y ? ou fournir les tableaux de données brutes ?
Bonjour Jocelyn,
Content que ça t’aide 🙂
Grâce à ton commentaire je viens de me rendre compte que le texte alternatif a sauté… j’y avais inclut le résumé des différentes valeurs… je vais voir si je trouve le temps de les refaire.
Après je n’ai volontairement pas détaillé ni utilisée une autre échelle (moins facile d’accès quand on ne connaît pas), pour montrer que certaines valeurs sont dans un mouchoir de poche, dans un même ordre de grandeur (autour de 30s pour les 4 premiers niveau de Zstandard). Les valeurs précises ne sont de toute façon pas très importantes, tout cela dépend de beaucoup de facteurs et serait peu reproductible sur d’autres configurations… sans parler de l’extrapolation à 100Go, où quelques Mo/s de différence (de l’ordre de l’aléa statique au moment du test) peuvent assez vite faire varier le résultat.
Donc je ne préfère laisser comme ça, car cela évite qu’on en tire des conclusions trop précises 🙂
Salut lapin,
Suite à mon précédent billet mon précédent billet
Borg Backup n’utilise toujours d’un seul thread => qu’un seul thread
Parmi les 4 types d’algorithmes sont disponibles => étant disponibles
a priori celui qui compresse le mieux, mais aussi le plus lent. uniquement au niveau 6 (le niveau par défaut, et le plus important. => (uniquement au niveau 6, niveau par défaut, le plus haut) ?
Tcho !
Et ben, ça ne me réussi pas les relectures tard le soir ?
(et pourtant je pensais avoir corrigé les 2 premières coquilles ?)
Merci pour les signalements ! 🙂